概要
MSRA在目标检测方向Beyond Regular Grid的方向上越走越远,又一篇大作推出,相比前作DCN v1在COCO上直接涨了超过5个点,简直不要太疯狂。文章的主要内容可大致归纳如下:
- More dconv and Modulated donv:认为前作中卷积变形时容易采样到不好的位置,例如背景等无关信息,这对于检测是有伤害的,这一点从两个方面下手解决,一是堆叠更多的Deformable卷积(简称dconv),这个不必多说;二是增加调制(modulated)功能,提出Modulated Deformabel卷积(简称mdconv),企图在采样到无关位置时,自适应地将这些位置的权重调低,以缓解其带来的伤害。这两下子一稿,AP从38.0提升到了41.7。
- Feature Mimicking:由于Deformable ROI Pooling(简称dpool,加调制模块简称mdpool)会采样到ROI之外的内容,这些内容虽说具有更多的上下文信息,但毕竟不属于ROI本身,可能对结果造成伤害。所以作者认为应该让dpool或mdpool得到的特征更“像”RCNN的特征,于是采用了知识蒸馏(这东西最近似乎很屌)的方法,作者称之为R-CNN Feature Mimicking,实现了这一目标。个人对此非常惊讶,看上去是难以work的,真是没想到。。。AP从41.7又提到了43.1,简直不要太疯狂。
- 模型分析:JiFeng老师还展示了一些分析模型表现的可视化方法,这一点对于我等炼丹师非常有教育意义。
模型分析
作者给出了三种可视化方法进行模型的分析,目的是从中发现DCN v1存在的问题,这几个方法虽然不是原创,但不得不说用得非常好,值得学习。
- Effective receptive fields:感受野的概念不必多说,有效感受野顾名思义就是感受野中贡献突出的区域。通过计算网络中的节点对于图像中每个像素的梯度,梯度值相对较大的地方就是了,具体的做法可以参阅此处的引文。
- Effective sampling / bin locations:DCN v1中对dpool各个bin的采样作了可视化,但这些采样位置对于后续结果的相对贡献没有体现。同样地,作者也使用节点对于采样位置的梯度大小来说明。
- Error-bounded saliency regions:这个方法是借鉴显著性检测的思想。本文简称ESR,定义为:图像中一片最小的区域,这片区域对网络的响应与全图对网络的响应之差小于一个较小的bound。获得ESR的方法是逐步mask图像中的点,观察节点响应的变化,如果变化大于某个阈值,那么这个点就属于ESR。
如原文Figure 1,有朋友反映不太能get到这个图的点,这里简单分析一下。这个图是对conv5 stage的最后一层卷积运用上面三种方法分析的结果,第一列是个烧饼(小目标),第二列是人(大目标),第三列是背景,绿点是目标的中心,上面几种方法就是基于节点以这几个绿点为中心做卷积时的情况进行的(这句话真是绕)。可以看到,(a)的第一行,regular卷积的感受野是regular的网格,感受野内的权重中心高,四周低。而dconv和mdconv的感受野理论上是全图,dconv比regular conv权重更集中于目标本身,而mdconv又比dconv更牛逼。其他两行要表达的东西其实类似。作者基于此归纳出的结论参考原文,基本也就是这意思。
More Deformable ConvNets
为了更好地建模几何形变,当然要堆叠更多的dconv,前作中只在conv5阶段用了3层dconv,性能就饱和了,但那是在PASCAL上的结果,COCO比PASCAL要复杂得多(当然训练数据量多也是原因之一),所以作者把conv3-conv5三个阶段12层conv都换成了dconv,妥妥的涨点。不过这不是主要的创新。
Modulated Deformable Modules
为了防止卷积变形时focus到无关位置,作者在dconv中加了一个调制项,
\[y(p) = \sum_{k=1}^{K} w_k \cdot x(p+p_k+\Delta p_k)\cdot \Delta m_k\] 符号就不多解释了,最后一项就是可学习的调制项,当采样点focus到无关位置时,这一项置0就可以挽回大局。调制项与前面的offset项用同样的方法获得,就是接一个旁支,之前输出2K个channel,现在输出3K个channel就是了。注意,看起来调制项和卷积核的参数w貌似是一回事,可以合写成一项,其实这是完全不同的,w是模型本身的参数,调制项是从输入特征中计算出来的,可以根据输入的不同自适应地去完成自己的使命。 另外也将dpool改进成了mdpool,也是乘了一个调制项,一样的道理,在此不再赘述。R-CNN Feature Mimicking
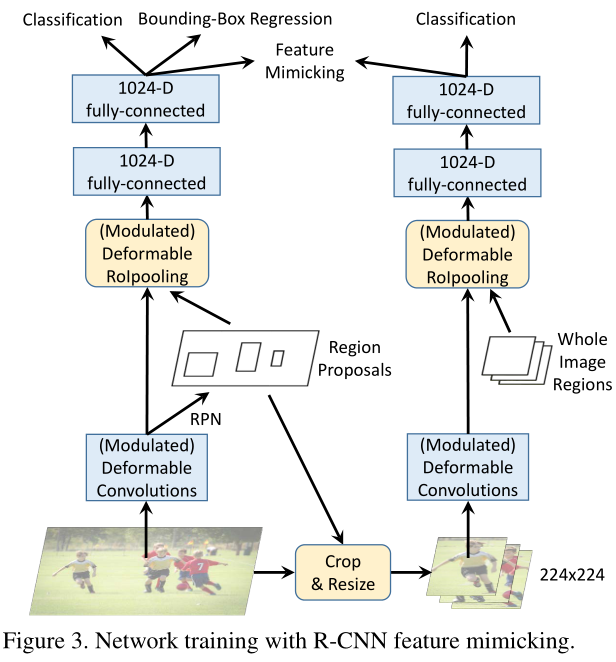
对于这一点我个人的疑惑是比较大的,这种trick能够work我感到惊讶和佩服。操作的方法就是模型蒸馏那一套,这个东西最近挺火的,最近还有一篇投稿到CVPR2019做pose的也用了这东西去做模型的压缩,效果也比较惊艳,不过这里是用来做特征的模仿,不是压缩。要解决的问题其实还是要筛除无关的上下文信息,作者认为加入调制项还不够,我们知道,R-CNN的做法不考虑ROI之外的内容,也就不会引入无关的context,所以直接模仿R-CNN提的特征就好了。具体做法参见原文Figure3,得到ROI之后,在原图中抠出这个ROI,resize到224x224,再送到一个RCNN中进行分类,这个RCNN只分类,不回归。然后,主网络fc2的特征去模仿RCNN fc2的特征,实际上就是两者算一个余弦相似度,1减去相似度作为loss即可,见原文公式(3)。这个东西确实是work了,不过个人有个重大疑问,或许也是可以改进的点,欢迎各位看官一起讨论:
主网络fc2的特征要用来分类,也要用来回归bbox,而RCNN的fc2特征只用来分类,让主网络的fc2特征去模仿RCNN,是不是会丢失定位信息?也就是说,Mimic Loss会不会跟bbox回归Loss产生某种意义上的冲突?能不能试试拆分一下fc2特征,把用于分类和用于回归的特征分开,只模仿用于分类的部分?当然,这个想法不成熟,有待商榷,不过感觉直接Mimic真的有一丢丢粗暴。
就这样吧,还要抓紧读JiFeng老师刚发的另一篇paper。=_=